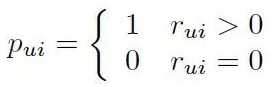Một Recommendation System (RecSys) gồm 5 thành phần chính:
Data Collection and Processing
Recommender Model
Recommendation Post-processing
Online Modules
User Interface
Hình 1: Các thành phần của một hệ thống gợi ý
Data Collection and Processing: Luôn là bước cực kỳ quan trọng trong bất kỳ bài toán data science nào. Đầu vào là rác cho đầu ra cũng là rác, vì vậy, cần phải tốn thời gian để xử lý đám data ngông cuồng, vô tổ chức bằng các kỹ thuật như data cleaning, normalization, feature selection and generation… Việc xử lý tốt data giúp cho chất lượng mô hình tuyệt vời hơn.
Recommender Model: Được đông đảo cư dân tìm đến khi bước đầu học machine learning, vì vậy rất nhiều người không biết về một hệ thống end-to-end. Với đầu vào là các thông tin đã được xử lý về users, items, mô hình sẽ dự đoán items nào được quan tâm bởi users nào.
Recommendation Post-processing: Các kết quả gợi ý được sinh ra bởi mô hình cần được xử lý nhằm đảm bảo rằng RecSys không quá ngu. Một số kết quả gợi ý bị loại bỏ trong khi một số khác được sắp xếp lại hoặc một số business logic như không gợi ý các loại items nào đó cho một user cụ thể cũng như cố gắng tăng sự đa dạng trong danh sách gợi ý cho users.
Online Modules: Chịu trách nhiệm cho việc phục vụ và thu thập hành vi người dùng. Một số dữ liệu được ghi lại nhằm báo cáo về hiệu suất hoạt động của hệ thống và tương tác từ người dùng. Các phương pháp online testing cũng có thể thực hiện ở bước này.
User Interface: Đây là nơi người dùng trực tiếp tương tác và trải nghiệm. UI chính là cái mặt tiền, xinh đẹp thì xài nhiều, xấu xí thì người ta bỏ đi. Ai cũng yêu cái đẹp và UI góp phần rất lớn trong việc thu hút người dùng sử dụng hệ thống
Năm thành phần cơ bản trên cấu thành một RecSys, có thể được phát triển song song hoặc tuần tự phụ thuộc vào từng dự án. Một số nơi có thể chia nhiều hơn, phức tạp hơn nhưng cơ bản chính là như vậy.
Khi thực hiện một mô hình phân tích hoặc dự báo nào đó, sau khi có kết quả từ mô hình, các kết quả có thể giúp các bên nghiệp vụ thấy được thông tin hữu ích hoặc đưa ra các kết quả dự báo. Tuy nhiên khi giao tiếp với các bên nghiệp vụ sẽ là khó khăn khi gặp phải các câu hỏi:
Nếu thực hiện phân tích này thu được được lợi ích gì?
Hay như: “Nếu thực hiện phân tích và chạy mô hình này sẽ giúp chúng tôi điều gì?”
Các thắc mắc như vậy ít nhiều gây khó cho những người làm data, vì chưa chạy mô hình, chưa phân tích thì chưa có kết quả, mà kể cả có kết quả thì chúng ta cũng không có (hoặc không rành) nghiệp vụ, rất khó để giải thích cho họ. Vì vậy kỹ năng giao tiếp và cách ứng dụng các mô hình vào thực tế cũng là một vấn đề đáng quan tâm. Bài viết này sẽ giới thiệu mô hình chuỗi thời gian và cách áp dụng chuỗi thời gian vào kinh doanh.
Giới thiệu về chuỗi thời gian
Phân tích chuỗi thời gian giúp cung cấp thông tin chi tiết về các đặc điểm dữ liệu và hiểu dữ liệu đang nói lên điều gì. Từ đó biết được các thông tin hữu ích và dự đoán giá trị tương lai.
Điều gì đã và đang xảy ra – Tình trạng ở quá khứ và hiện tại
Các chỉ số đã và đang diễn ra như thế nào? Hành vi của chỉ số đó diễn ra như thế nào?
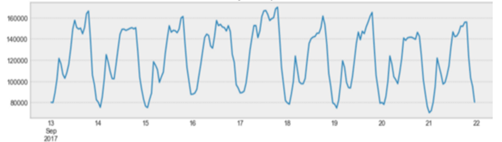
Với biểu đồ chuỗi thời gian, dễ dàng thấy được giá trị XẤP XỈ TẠI THỜI ĐIỂM (kỳ ) NÀO ĐÓ. Ví dụ thay vì biết ngày 28-7-2020 thu nhập của ngân hàng ACB là: 6 245 345 305 đ, các nhà quản lý chỉ cần số tương đối như khoảng 6 tỷ, khoảng từ 30-32 tỷ. Điều này giúp nhanh chóng biết được các con số mà không cần nhìn vào một bảng cáo cáo toàn số.
Hình 1
Đối với các nhà quản lý thậm chí là các nhân viên, nếu hàng ngày phải nhìn vào hàng trăm báo cáo tràn ngập số sẽ như thế nào? Chắc chắn mất rất nhiều thời gian và là ác mộng. Mặt khác về mặt trực giác thì khó mà tưởng tượng được độ lớn của các con số. Điều quan trọng là so sánh giữa nhiều kỳ diễn ra cùng lúc một cách nhanh chóng. Với biểu đồ, chỉ cần liếc mắt, lia ngang vào trục tung là có thể so sánh hàng loạt và ước lượng ra giá trị của một kỳ nào đó. Và so sánh giữa các kỳ với nhau một cách dễ dàng.
Xu thế và tốc độ tăng trưởng
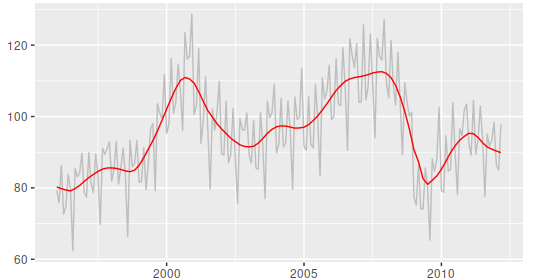
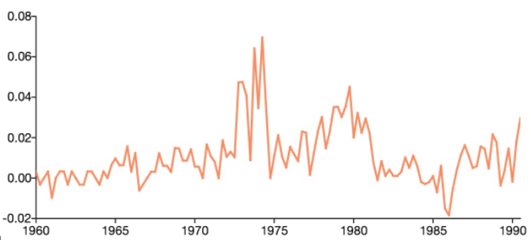
Chỉ cần một đường cong trơn lượn theo một chuỗi thời gian đã thấy rõ xu thế và tốc độ tăng trưởng của một chỉ số nào đó.
Hình 2
Ví dụ hình 2 trên, đường màu đỏ thể hiện xu thế với tốc độ tăng trưởng.
Từ 1995 – 1999 xu thế tăng chậm trong 4 năm đó tăng từ 80-82. Trong khoảng thời gian này tăng ổn định đều đều có 2 lần xuống đáy.
Từ 1999- 2001 tăng rất mạnh từ 82 – 110 và trong năm 2002 là đỉnh điểm trong khoảng thời gian này.
2001 -2003 giảm tương đối từ 110 – 90.
Từ 2003 – 2008 tăng tương đồi dài với tốc độ tăng tương đối đều từ 90- 111.
Từ 2008 – 2010 giảm đột ngột xuống đáy từ 111 – 82, giảm rất đều.
Từ 2010 – 2012 tăng tương đối 82-92.
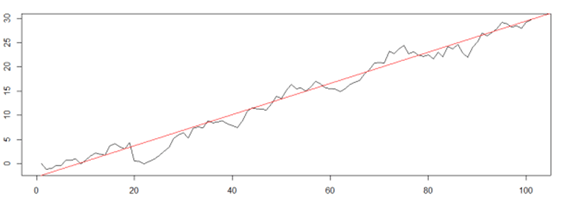
Nhìn vào độ dốc của đường xu thế, về mặt trực giác độ dốc thể hiện sự tăng trưởng. Mặt khác so sánh với tốc độ chuẩn (tốc độ mục tiêu) để dễ dàng thấy được tốc độ tăng trưởng so với kế hoạch.
Hình 3
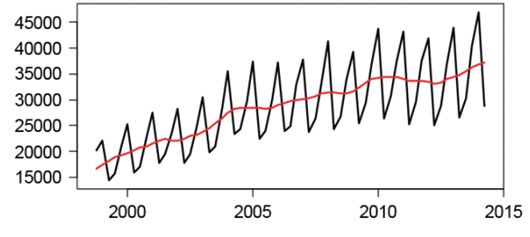
Mùa vụ và tính chu kỳ
Tính mùa vụ và tính chu kỳ của chuỗi cho thấy sự lặp lại của các giá trị một cách đều đặn.
Hình 4
Hình 4 cho thấy tính lặp lại định kỳ và khoảng biên độ lên xuống gần như không đổi từ 2004 – 2015
Chu kỳ lặp lại hàng năm. Từ điểm cao nhất – thấp nhất 15000. Và trong mỗi chu kỳ chỉ có một điểm cao nhất và điểm thấp nhất. Từ điểm cao nhất xuống rất dốc và đều đặn đến điểm thấp nhất. Tuy nhiên từ điểm thấp nhất lên điểm cao nhất thì ban đâu tăng mạnh, lấy đà tại một điểm gãy, sau đó tăng đều đặn một cách liên tục.
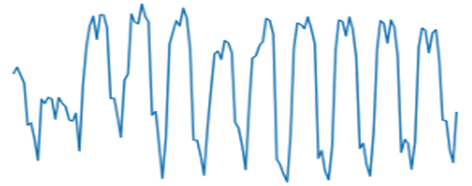
Hình 5
Hình 5 thể hiện tính mùa vụ lặp lại khá rõ. Tuy nhiên điểm có 2 điểm cực đại trong mỗi mùa vụ. Ta chiếu các điểm này vào thời gian cụ thể, sau đó đối chiếu với thời điểm đó đã xảy ra điều gì? Ta sẽ biết lý do gây ra các điểm này là do yếu tố nào gây lên.
Hình 6
Hình 6 cho thấy tính mùa vụ thể hiện phức tạp hơn. Trong chu kỳ mùa vụ dài lại có tính mùa vụ nhỏ. Mỗi một điểm cực đại có xu hướng trải tù và gần lên đỉnh thì tăng rất chậm. Sau khi xuống cực tiểu thì lên một “ngọn núi nhỏ” , biến động xuống rồi lại lên cực đại. Chiếu các điểm này xuống trục hoành cho biết thời gian, kết hợp với các sự kiện trên hệ thống và các sự kiện xảy ra bên ngoài cho biết các nguyên nhân nào gây ra điều này.
Sự bất thường
Hai câu hỏi luôn muốn được trả lời:
Điểm này là bình thường hay bất thường?
Điểm bình thường hay bất thường này do điều gì gây ra.
Hình 7
Trong hình 7 thể hiện rằng:
Giai đoạn 1973, 1974, 1975 đã xảy ra sự bất thường. Liệu đây là sự bất thường thực sự hay chỉ là sự kiện bình thường? Và điều này bắt nguồn từ bên trong xảy ra hay bên ngoài?
Chiếu các điểm này vào trục hoành thu được các năm 1973, 1974, 1975. Xem xét trong hệ thống của nội bộ có điều gì xảy ra dẫn đến điều này. Ví dụ do chúng ta áp dụng 1 chiến dịch khuyến mại là giảm giá 40% cho tất cả các mặt hàng dẫn đến tăng đột biến gần gấp đôi. Sau khi hết chương trình khuyến mại thì giảm xuống gần gấp đôi nhưng vẫn cao hơn so với trước khuyến mại và sau đó có sự tăng trưởng rõ nét trong 5 năm liền. Điều này cao hơn đáng kể giai đoạn trước khuyến mại 1968, 1969, 1970, 1071, 1972. Từ đây cho chúng ta 2 insight quan trọng:
Khi áp dụng khuyến mại khoảng 40 % thì tăng gấp đôi.
Nếu áp dụng chương trình khuyến mại này trong 3 kỳ thì sau đó không áp dụng nữa thì vẫn có hiệu quả tăng đều trong 5 kỳ liên tiếp
Vậy chương trình khuyến mại này cho ta hiệu quả tích cực.
Nếu áp dụng chương trình khuyến mại này (3 kỳ) tốn kém quá. Vậy ta thử chỉ áp dụng 2 kỳ khuyến mại. Giả sử có hai tình huống sau xảy ra:
Có tăng gấp đôi nhưng sau khi hết khuyến mại thì trở về giống trước đó. Điều này đi đến kết luận khuyến mại 2 kỳ không làm tăng hiệu quả (sau khi hết chương trình khuyến mại). Do đó, nếu muốn hiệu quả thì phải khuyến mại ba kỳ.
Có tăng gấp đôi, sau khi hết khuyến mại vẫn tăng (hiệu quả) giống như áp dụng cho 3 kỳ. Điều này cho một kết luận mới: Chỉ cần khuyến mại hai kỳ là đủ hiệu quả.
Từ (1) nếu thấy tốn kém quá, lần sau thử khuyến mại có 30%. Và nếu thấy tốt như khi khuyến mại 40% (nghĩa là sau khi hết chương trình khuyến mại và vẫn tăng tương tự như khuyến mại 40%). Thì sau này chỉ cần khuyến mại 30% để cho kết quả tương tự.
So sánh các chuỗi thời gian
Khi nhìn vào các báo cáo có sắn, thật khó để thấy được sự so sánh các thông tin hữu ích giữa các chuỗi thời gian: Ví dụ doanh số ở SG và HN so với nhau theo thời gian như thế nào:
Hình 8
Không thể kết luận rằng Sài Gòn kinh doanh hiệu quả hơn Hà Nội hay Hà Nội kinh doanh tốt hơn Sài Gòn khi chỉ dựa vào một vài các con số (mà nếu có thể thấy được thì không ai dám nhìn vào hàng chục con số trong các báo cáo):
Ví dụ Sài Gòn thể hiện bằng màu đỏ, Hà Nội màu xanh: Ta thấy hành vi tương tự giữa hai chuỗi thời gian. Tuy nhiên lại thấy Sài Gòn luôn đi trước và Hà Nội luôn đi sau hai kỳ. Vì vậy có thể rút ra kết luận Sài Gòn là thị trường dẫn dắt và trước Hà Nội một khoảng thời gian là 2 kỳ (giả sử các mặt hàng và tất cả mọi thứ giống hệt nhau).
Do đó có thể áp dụng thử nghiệm thị trường, ta nên thử nghiệm ở Sài Gòn trước. Nếu đạt được thành công A cho thị trường Sài Gòn, sau 2 kỳ, việc áp dụng điều tương tự cho Hà Nội cũng đem lại kết quả tương tự.
Giả sử chưa có số liệu chứng minh thị trường Hà Nội là thị trường dẫn dắt. Do đó nếu áp dụng cho thị trường Hà Nội thì có hai điều sau có thể xảy ra:
Có thể không đạt được thành công A ở thị trường Hà Nội (vì trong quá khứ Hà Nội cần một thị trường dẫn dắt đó là Sài Gòn)
Giả sử đạt được thành công A ở thị trường Hà Nội thì cũng chưa có điều gì chứng minh là cũng sẽ thành công tương tự ở thị trường Sài Gòn (vì không có số liệu chứng minh Hà Nội là thị trường dẫn dắt cho thị trường Sài Gòn).
Dự báo
Dự báo luôn là tham vọng của con người, nếu có quá nhiều yếu tố (features) tác động (đến số lượt view của fb chẳng hạn) hoặc không thu thập được các yếu tố quan trọng, khi đó dự báo chuỗi thời gian sẽ là cứu cánh cho chúng ta.
Hình 9
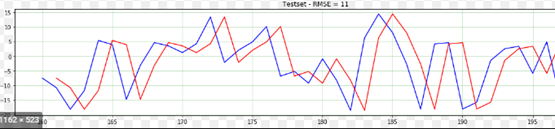
Khi số liệu chưa đủ để thực hiện mô hình toán học thì đồ thị cũng ngầm cho 1 dự báo. Nhìn vào hình 9 có thể dự báo là đường màu đỏ sẽ đạt mức 40 vào năm 2010 và đường màu xanh sẽ chạm mốc 10 vào năm 2010.
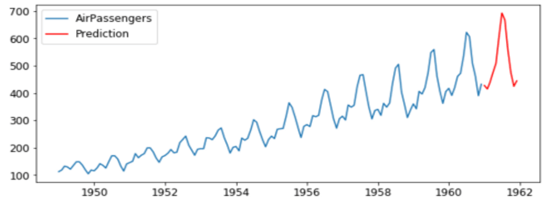
Hình 10 bên dưới có thể mường tượng rằng dự báo sẽ là phần màu đỏ trong năm 1961 và 1962.
Hình 10
Khi số liệu đủ lớn, việc áp dụng các mô hình dự báo sẽ cho kết quả dự có thể chính xác hơn đồ thị hoặc cảm tính.
Mọi thành viên viết bài bắt buộc phải tuân thủ các chuẩn mực quy tắc sau đây:
Đạo văn (plagiarism): Tuyệt đối nghiêm cấm đạo văn, mọi hình ảnh, tài liệu, số liệu,… bắt buộc phải trích dẫn tác giả. Khuyến khích trích nguồn theo chuẩn IEEE, APA6.
Các thành viên được yêu cầu viết bài khách quan nhất có thể, nghiêm cấm các hành vi bôi nhọ danh dự cá nhân, tổ chức, nhà nước….
Phải có bố cục rõ ràng, nội dung nên mạch lạc theo bố cục đó. Công thức toán được khuyến khích viết bằng LaTex
Nội dung không giới hạn với mục đích chính đáng, đóng góp cho sự phát triển cộng đồng, đất nước.
Không quên khát vọng ban đầu, quay lại vẫn là thiếu niên.
Matrix factorization using Alternating Least Squares
Matrix factorization using Bayesian Personalized Ranking
Code
1. Tổng quan: Trước khi diễn ra cuộc tranh tài RecSys do Nexflix tổ chức, hầu hết các RecSys được xây dựng dựa trên explicit data – loại data biểu thị trực quan ý kiến người dùng (tích cực hoặc tiêu cực). Cùng với sự cải tiến trong các kỹ thuật thu thập dữ liệu và xu hướng ít rating của người dùng, các loại dữ liệu implicit đã có đất dụng võ và trở nên phổ biến hơn trong cả nghiên cứu và công nghiệp.
2. Explicit vs Implicit Feedback Explicit Feedback: Được cung cấp bởi người dùng một cách cố ý, nhằm diễn đạt sự hài lòng đối với một sản phẩm nào đó, có thể là rating, thumps up, thumps down.. Implicit Feedback: Không được cung cấp một cách cố ý bởi người dùng, được thu thập thông qua cookies, media-types như click, view, purchase history, bookmark, impression… Một số đặc điểm của dữ liệu implicit như sau:
No negative feedback: Trong implicit data, chỉ có các phản ánh tích cực như clicks, purchase và không cách nào để nói rằng missing data là bởi vì người dùng không tích nó.
Noisy: Một cái click, view có thể là random hoặc bị cấn phím, chuột hoặc do những đứa trẻ phá phách làm cho loại dữ liệu này nhiễu rất nhiều. Tuy nhiên, có thể khắc phục do lượng lớn khối lượng dữ liệu này.
Preference vs confidence: Tần số của từng sự kiện trong implicit data chưa chắc đã biểu diễn mức độ quan tâm của người dùng đối với một sản phầm nào đó, cần có các metrics cho thấy độ tin cậy về sự quan tâm này.
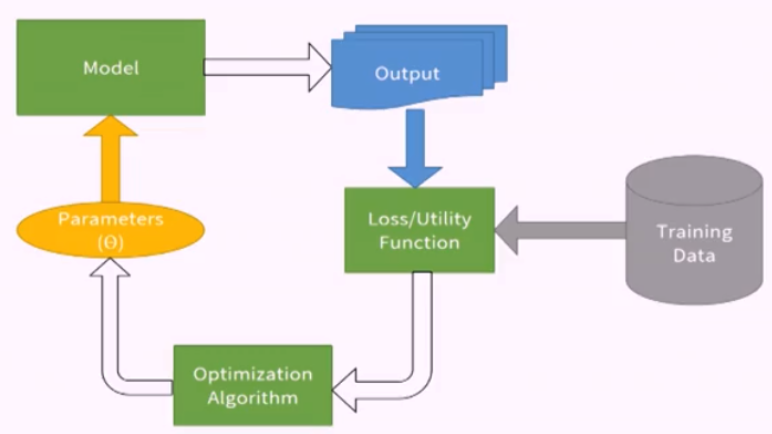
3. Matrix factorization Các bước xây dựng mô hình trong RecSys cũng giống với việc xây dựng bất kỳ mô hình nào trong machine learning (hình 1). Trong đó:
Loss/Utility function: Đo lường liệu mô hình đã đúng với thực tế hay chưa
Optimization Algorithm: Công cụ tăng tốc việc học
Model: Phương trình đã được học (các kỹ thuật matrix factorization thuộc phần này)
Hình 1: Các bước xây dựng mô hình của một thuật toán machine learning
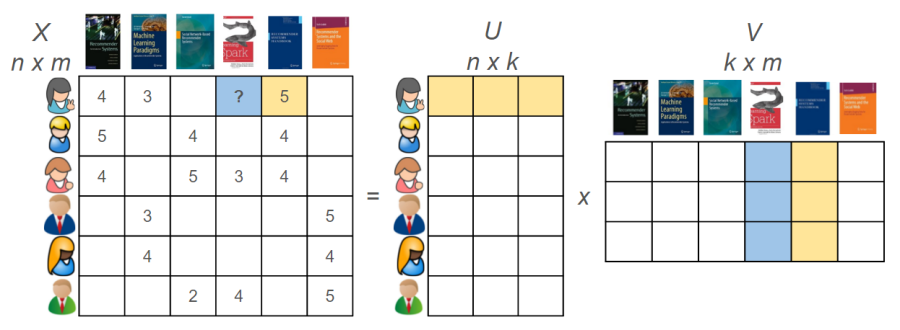
Matrix factorization là kỹ thuật phân rã một ma trận thành các ma trận với số chiều nhỏ hơn nhằm tối ưu hoá việc tính toán. Trong RecSys, một ma trận X với n hàng là users, m cột tương ứng với items, và giá trị là rating của user đối với item tương ứng được phân rã thành 2 ma trận U(n users với k latent factors) và V(m items với k latent factors) (hình 2)
Hình 2: Matrix factorization
4. Matrix factorization for Explicit data Hàm mất mát (cost function):
Hình 3: Hàm mất mát
chính là giá trị rating thực tế mà use đã đánh giá (nằm bên bảng X hình 2), là giá trị user latent factors nằm trong bảng U và là giá trị item latent factor nằm trong bảng V. Một cách đơn giản, hàm mất mát này tối thiểu sai số các giá trị trong bảng X và các giá trị trong bảng UxV. Phần còn lại chính là regularization nhằm tránh overfitting. Hàm này trả lời cho câu hỏi các giá trị dự đoán có đủ tốt so với thực tế hay không dựa vào sự so sánh các giá trị dự đoán và thực tế. Các giá trị trống trong bảng X sau cùng được điền bằng các giá trị tương ứng chính là rating cần dự đoán. Vì cách học này có nhiều nghiệm xấp xỉ và k chiều chính là hyperparameter được lựa chọn nên còn được gọi là Latent factors model. Việc tối thiểu hàm mất mát cơ bản dựa trên thuật toán tối ưu hoá có thể xem tại đây. Vậy đầu ra của mô hình chính là các latent factors cho users và items.
Hai kỹ thuật matrix factorization thường dùng trong xây dựng RecSys dựa trên implicit data là Alternating Least Squares và Bayesian Personalized Ranking
5. Matrix factorization using Alternating Least Squares Phần này dựa trên bài báo của tác giả Yifan Hu, Yehuda Koren và Chris Volinsky. Tương tự với phương trình ở hình 3, tuy nhiên được biến đổi đôi chút.
Định nghĩa preference của user u trên item i, với đại diện cho user u tương tác với item i. Nếu có user u có tương tác với item i (view, click, purchase…) thì , suy ra và ngược lại. Một cách đơn giản, nếu user u có tương tác với item i, nếu user u không tương tác với item i
Các kỹ thuật xây dựng một RecSys (Recommendation System – Hệ thống khuyến nghị) chia làm 2 loại chính:
Các kỹ thuật truyền thống (traditional)
Kỹ thuật phi truyền thống (advanced or non-traditional)
Tổng quan về các kỹ thuật cũng như ưu, nhược điểm của chúng được trình bày tại awesome post. Loạt bài RecSys được code xuyên suốt từ Content-based, Collaborative filtering, Hybrid. Post này trình bày về phương pháp content-based filtering.
Hình 1: Traditional RecSys techniques
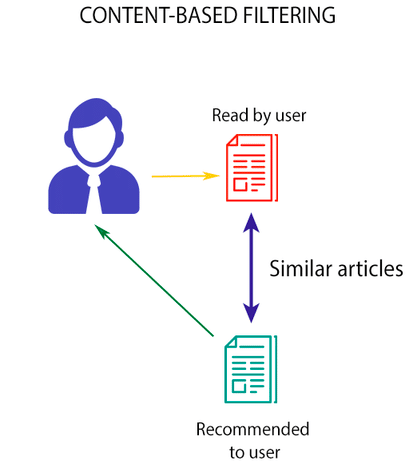
Ý tưởng: Đề xuất các items tương tự với các items đã được tương tác bởi users (hình 2)
Hình 2: Đề xuất tờ báo (phía dưới) tương tự với tờ báo (bên trên) đã được đọc bởi user
Hỏi: Thế nào là các items tương tự nhau? Đáp: Các items giống nhau dựa trên 1 khía cạnh nào đó. Ví dụ: Sữa vinamilk giống TH true milk hơn là cá, vì đều là sữa… Hỏi: Tiêu chuẩn nào để xác định các items giống nhau? Đáp: Ba kỹ thuật thông dụng thường dùng đo độ tương tự: Cosine similarity, Euclidian Distance và Pearson Correlation.
Cosine Similarity: là giá trị cosine của góc giữa hai vector (giá trị trong đoạn [-1, 1]). Cosine là lớn, tức góc càng nhỏ, hai vectors càng tương tự nhau. Để lý rằng, 2 vectors trùng nhau, góc giữa chúng là 0 độ, cosine bằng 1. Ngược lại, 2 vectors có chiều ngược nhau tạo thành góc 180 độ,
Hình 3: Cosine similarity
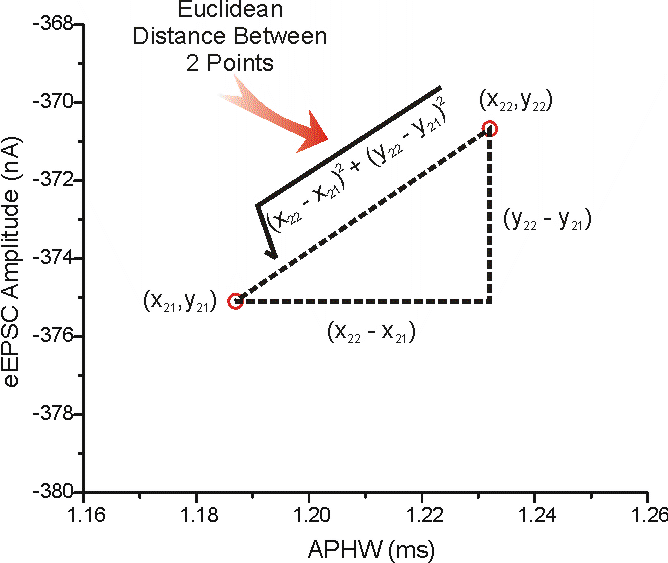
Euclidean Distance: đơn giản là đường thẳng nối 2 điểm trong 1D, trong 2D là cạnh huyền của 1 tam giác… Khoảng cách euclidean càng cao, 2 vectors càng khác nhau, độ tương tự càng thấp, ví như khoảng cách địa lý, càng xa lại càng khác nhau.
Hình 4: Khoảng cách Euclidean giữa hai điểm
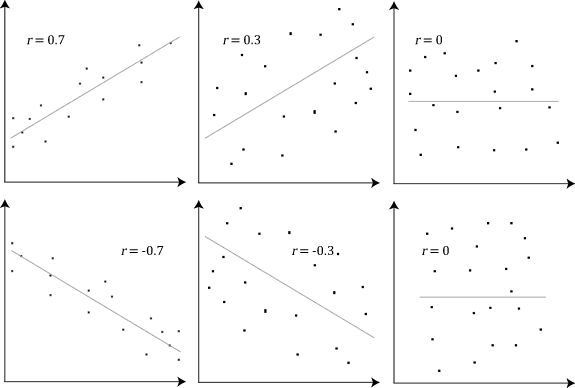
Pearson Correlation: đo lường độ tương quan giữa 2 vectors, giá trị trong đoạn [-1, 1], -1 nghĩa là tương quan âm, +1 là tương quan dương, 0 là không tương quan (randomness). Độ tương quan càng cao, 2 vectors càng giống nhau.
Hình 5: Ví dụ về pearson correlation
Một lưu ý nhỏ là các phép đo độ similarity là đối xứng. Nghĩa là similarity của x so với y bằng y so với x
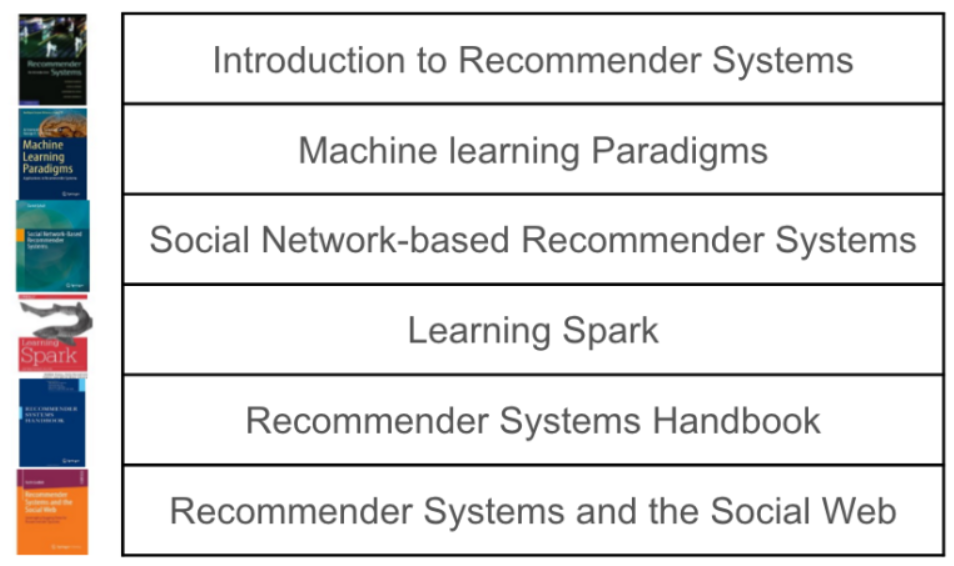
Ví dụ: Hình bên dưới mô tả người dùng đã tương tác với một số sách, nhiệm vụ khuyến nghị các loại sách khác mà họ cảm thấy hứng thú. Dữ liệu gồm book description, book_id và user_id. Giả sử đơn giản rằng hệ thống có 6 người dùng và 6 cuốn sách, mục tiêu khuyến nghị 2 trong số 6 cuốn sách này. Người dùng thứ nhất đã đọc và rating các sách: Introduction to Recommender System, Machine Learning Paradigms và Recommender System Handbook, vậy trong 3 cuốn còn lại, 2 cuốn nào được ưu tiên đề xuất hơn?
Hình 6: Dữ liệu người dùng
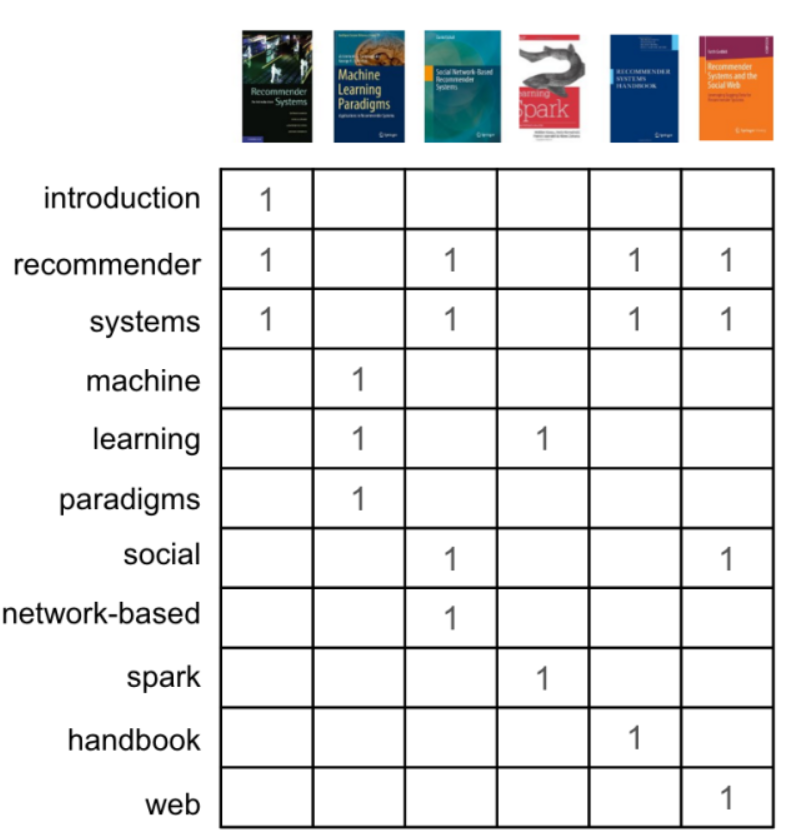
Như đã đề cập phía trên, phương pháp Content-based dựa trên ý tưởng đề xuất các cuốn sách mà người dùng chưa đọc tương tự với những cuốn sách người dùng đã đọc trong quá khứ. Vì vậy, cần xây dựng một similarity matrix cho tập các cuốn sách này.
Hình 7: Tiêu đề sách
Thông thường, các kỹ thuật xử lý ngôn ngữ được áp dụng cho việc trích xuất thông tin từ các content như Count Vector, TF-IDF, CBOW…(có thể tham khảo các kỹ thuật word embeddings tại đây)
Hình 8: Word presentation cho tiêu đề sách
Sau khi xây dựng xong word presentation vector, dễ dàng tính toán được similarity của từng đôi một các cuốn sách. Hình 9 dùng cosine similarity xây dựng một similarity matrix. Để ý rằng các giá trị trên đường chéo chính luôn bằng 1 do tính toán cho chính nó.
Hình 9: Similarity matrix được tính theo cosine similarity
Yêu cầu chỉ cho phép đề xuất 2 cuốn sách, dựa vào similarity matrix, chọn ra 2 cuốn sách có similarity cao nhất tương ứng với ba cuốn sách mà người dùng thứ nhất đã đọc:
Introduction to Recommender System: 2 cuốn sách tương tự là Recommendation System Hanbook và Recommendation System and the Social Web (2 quyển cuối cùng) với cosine similarity lần lượt là 0.67 và 0.58
Machine Learning Paradigms: Learning Spark (cuốn màu trắng, đỏ có con cá ở giữa) với 0.41
Recommender System Handbook: Recommendation System and the Social Web và Introduction to Recommender System ứng với 0.58 và 0.67
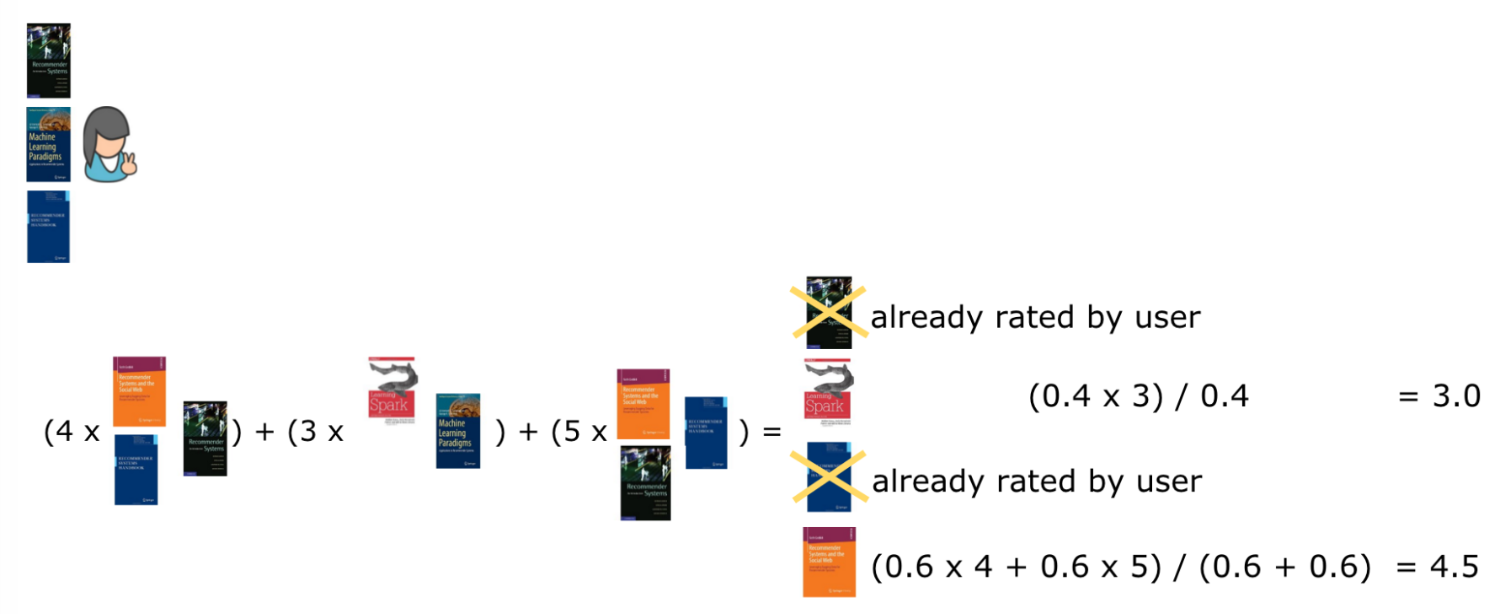
Các sách đã được đọc bởi người dùng cần được loại bỏ khỏi danh sách khuyến nghị, vậy chỉ cần tính toán rating cho 2 cuốn Recommendation System and the Social Web và Learning Spark. Cách tính như sau:
Tổng của (similarity giữa sách đã đọc và sách khuyến nghị * rating của sách đã đọc) / (tổng của similarity giữa sách đã đọc và sách khuyến nghị)
Do sách Recommendation System and the Social Web (cuốn vàng) tương tự với Introduction to Recommender System (0.67) được rating 4 và Recommender System Handbook (0.58) được rating 5 nên công thức tính như hình 10 (similarity chỉ lấy 1 chữ số sau dấy phẩy). Cách tính cho sách Learning Spark tương tự.
Hình 10: Tính toán rating cho các cuốn người dùng chưa đọc

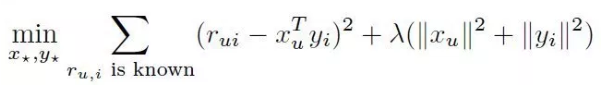
 chính là giá trị rating thực tế mà use đã đánh giá (nằm bên bảng X hình 2),
chính là giá trị rating thực tế mà use đã đánh giá (nằm bên bảng X hình 2),  là giá trị user latent factors nằm trong bảng U và
là giá trị user latent factors nằm trong bảng U và 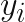 là giá trị item latent factor nằm trong bảng V.
là giá trị item latent factor nằm trong bảng V.  tương ứng chính là rating cần dự đoán. Vì cách học này có nhiều nghiệm xấp xỉ và k chiều chính là hyperparameter được lựa chọn nên còn được gọi là Latent factors model. Việc tối thiểu hàm mất mát cơ bản dựa trên thuật toán tối ưu hoá có thể xem tại
tương ứng chính là rating cần dự đoán. Vì cách học này có nhiều nghiệm xấp xỉ và k chiều chính là hyperparameter được lựa chọn nên còn được gọi là Latent factors model. Việc tối thiểu hàm mất mát cơ bản dựa trên thuật toán tối ưu hoá có thể xem tại  của user u trên item i, với
của user u trên item i, với 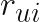 đại diện cho user u tương tác với item i. Nếu có user u có tương tác với item i (view, click, purchase…) thì
đại diện cho user u tương tác với item i. Nếu có user u có tương tác với item i (view, click, purchase…) thì 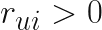 , suy ra
, suy ra  và ngược lại.
và ngược lại.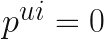 nếu user u không tương tác với item i
nếu user u không tương tác với item i