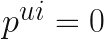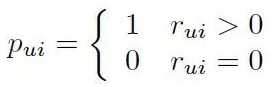Nội dung:
- Tổng quan
- Implicit vs Explicit Feedback
- Matrix factorization
- Matrix factorization for Explicit data
- Matrix factorization using Alternating Least Squares
- Matrix factorization using Bayesian Personalized Ranking
- Code
1. Tổng quan:
Trước khi diễn ra cuộc tranh tài RecSys do Nexflix tổ chức, hầu hết các RecSys được xây dựng dựa trên explicit data – loại data biểu thị trực quan ý kiến người dùng (tích cực hoặc tiêu cực). Cùng với sự cải tiến trong các kỹ thuật thu thập dữ liệu và xu hướng ít rating của người dùng, các loại dữ liệu implicit đã có đất dụng võ và trở nên phổ biến hơn trong cả nghiên cứu và công nghiệp.
2. Explicit vs Implicit Feedback
Explicit Feedback: Được cung cấp bởi người dùng một cách cố ý, nhằm diễn đạt sự hài lòng đối với một sản phẩm nào đó, có thể là rating, thumps up, thumps down..
Implicit Feedback: Không được cung cấp một cách cố ý bởi người dùng, được thu thập thông qua cookies, media-types như click, view, purchase history, bookmark, impression… Một số đặc điểm của dữ liệu implicit như sau:
- No negative feedback: Trong implicit data, chỉ có các phản ánh tích cực như clicks, purchase và không cách nào để nói rằng missing data là bởi vì người dùng không tích nó.
- Noisy: Một cái click, view có thể là random hoặc bị cấn phím, chuột hoặc do những đứa trẻ phá phách làm cho loại dữ liệu này nhiễu rất nhiều. Tuy nhiên, có thể khắc phục do lượng lớn khối lượng dữ liệu này.
- Preference vs confidence: Tần số của từng sự kiện trong implicit data chưa chắc đã biểu diễn mức độ quan tâm của người dùng đối với một sản phầm nào đó, cần có các metrics cho thấy độ tin cậy về sự quan tâm này.
3. Matrix factorization
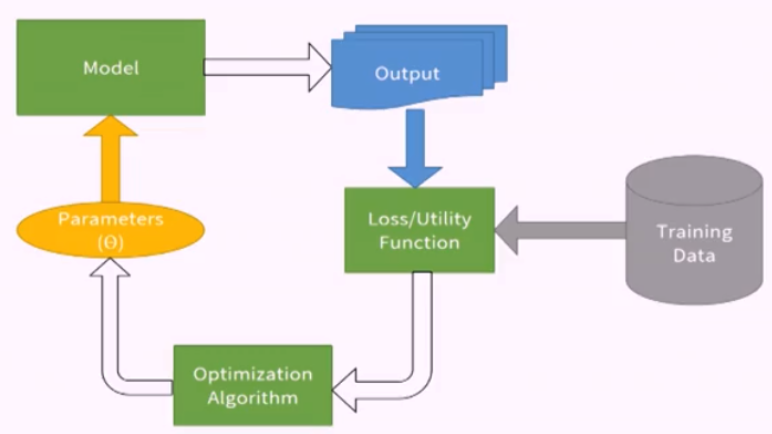
Các bước xây dựng mô hình trong RecSys cũng giống với việc xây dựng bất kỳ mô hình nào trong machine learning (hình 1). Trong đó:
- Loss/Utility function: Đo lường liệu mô hình đã đúng với thực tế hay chưa
- Optimization Algorithm: Công cụ tăng tốc việc học
- Model: Phương trình đã được học (các kỹ thuật matrix factorization thuộc phần này)
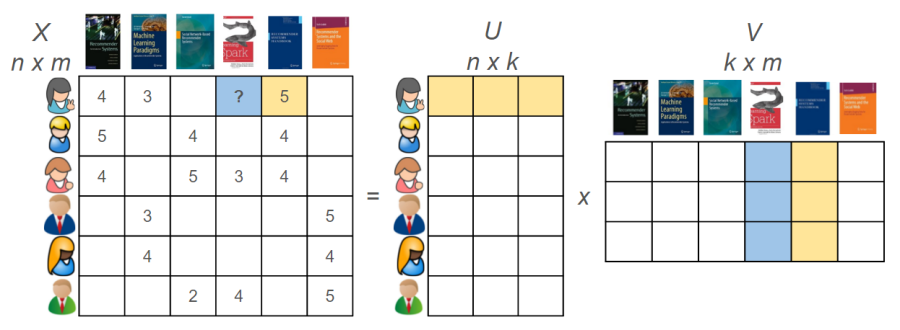
Matrix factorization là kỹ thuật phân rã một ma trận thành các ma trận với số chiều nhỏ hơn nhằm tối ưu hoá việc tính toán. Trong RecSys, một ma trận X với n hàng là users, m cột tương ứng với items, và giá trị là rating của user đối với item tương ứng được phân rã thành 2 ma trận U(n users với k latent factors) và V(m items với k latent factors) (hình 2)
4. Matrix factorization for Explicit data
Hàm mất mát (cost function):
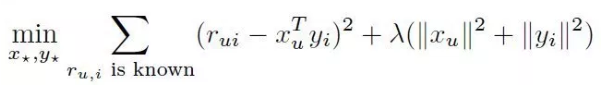


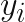
Một cách đơn giản, hàm mất mát này tối thiểu sai số các giá trị trong bảng X và các giá trị trong bảng UxV. Phần còn lại chính là regularization nhằm tránh overfitting. Hàm này trả lời cho câu hỏi các giá trị dự đoán có đủ tốt so với thực tế hay không dựa vào sự so sánh các giá trị dự đoán và thực tế.
Các giá trị trống trong bảng X sau cùng được điền bằng các giá trị 
Vậy đầu ra của mô hình chính là các latent factors cho users và items.
Hai kỹ thuật matrix factorization thường dùng trong xây dựng RecSys dựa trên implicit data là Alternating Least Squares và Bayesian Personalized Ranking
5. Matrix factorization using Alternating Least Squares
Phần này dựa trên bài báo của tác giả Yifan Hu, Yehuda Koren và Chris Volinsky. Tương tự với phương trình ở hình 3, tuy nhiên được biến đổi đôi chút.
Định nghĩa preference 
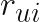
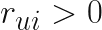

Một cách đơn giản,