Các kỹ thuật xây dựng một RecSys (Recommendation System – Hệ thống khuyến nghị) chia làm 2 loại chính:
- Các kỹ thuật truyền thống (traditional)
- Kỹ thuật phi truyền thống (advanced or non-traditional)
Tổng quan về các kỹ thuật cũng như ưu, nhược điểm của chúng được trình bày tại awesome post. Loạt bài RecSys được code xuyên suốt từ Content-based, Collaborative filtering, Hybrid. Post này trình bày về phương pháp content-based filtering.

Ý tưởng: Đề xuất các items tương tự với các items đã được tương tác bởi users (hình 2)
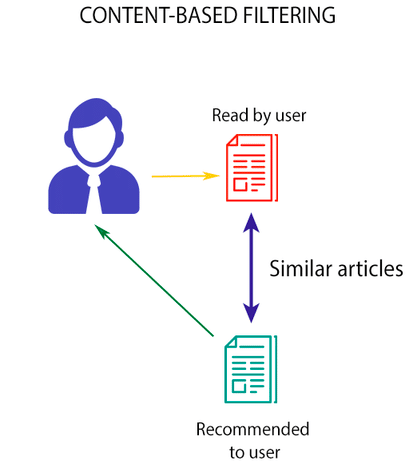
Hỏi: Thế nào là các items tương tự nhau?
Đáp: Các items giống nhau dựa trên 1 khía cạnh nào đó. Ví dụ: Sữa vinamilk giống TH true milk hơn là cá, vì đều là sữa…
Hỏi: Tiêu chuẩn nào để xác định các items giống nhau?
Đáp: Ba kỹ thuật thông dụng thường dùng đo độ tương tự: Cosine similarity, Euclidian Distance và Pearson Correlation.
Cosine Similarity: là giá trị cosine của góc giữa hai vector (giá trị trong đoạn [-1, 1]). Cosine là lớn, tức góc càng nhỏ, hai vectors càng tương tự nhau. Để lý rằng, 2 vectors trùng nhau, góc giữa chúng là 0 độ, cosine bằng 1. Ngược lại, 2 vectors có chiều ngược nhau tạo thành góc 180 độ,

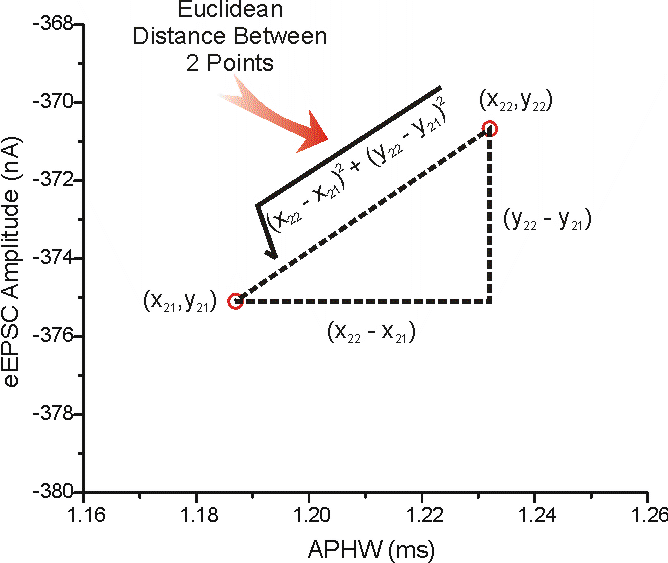
Euclidean Distance: đơn giản là đường thẳng nối 2 điểm trong 1D, trong 2D là cạnh huyền của 1 tam giác… Khoảng cách euclidean càng cao, 2 vectors càng khác nhau, độ tương tự càng thấp, ví như khoảng cách địa lý, càng xa lại càng khác nhau.
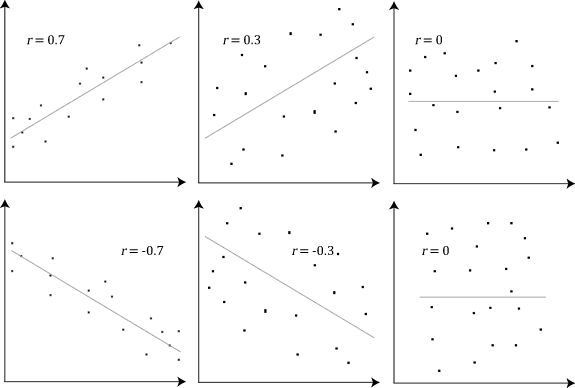
Pearson Correlation: đo lường độ tương quan giữa 2 vectors, giá trị trong đoạn [-1, 1], -1 nghĩa là tương quan âm, +1 là tương quan dương, 0 là không tương quan (randomness). Độ tương quan càng cao, 2 vectors càng giống nhau.
Một lưu ý nhỏ là các phép đo độ similarity là đối xứng. Nghĩa là similarity của x so với y bằng y so với x
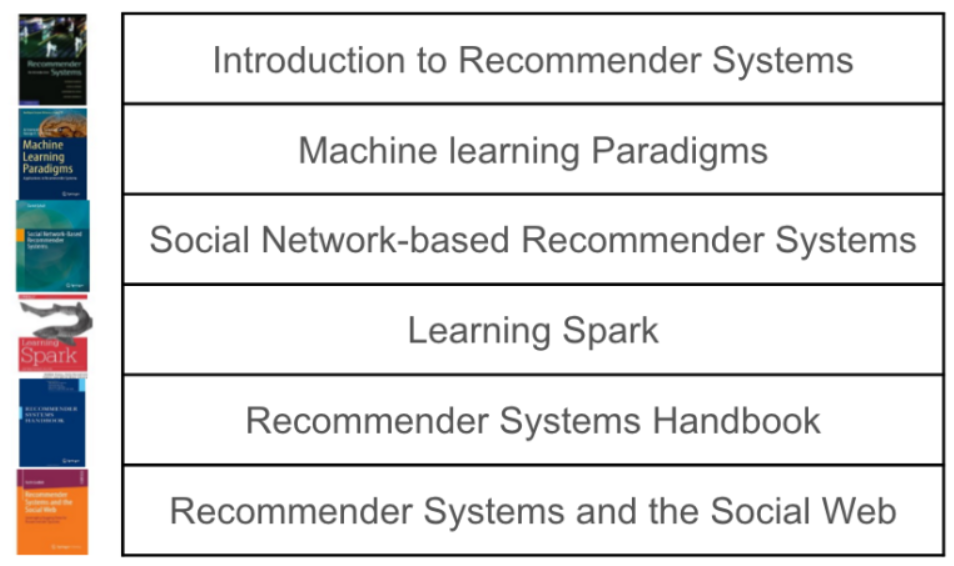
Ví dụ: Hình bên dưới mô tả người dùng đã tương tác với một số sách, nhiệm vụ khuyến nghị các loại sách khác mà họ cảm thấy hứng thú. Dữ liệu gồm book description, book_id và user_id. Giả sử đơn giản rằng hệ thống có 6 người dùng và 6 cuốn sách, mục tiêu khuyến nghị 2 trong số 6 cuốn sách này. Người dùng thứ nhất đã đọc và rating các sách: Introduction to Recommender System, Machine Learning Paradigms và Recommender System Handbook, vậy trong 3 cuốn còn lại, 2 cuốn nào được ưu tiên đề xuất hơn?

Như đã đề cập phía trên, phương pháp Content-based dựa trên ý tưởng đề xuất các cuốn sách mà người dùng chưa đọc tương tự với những cuốn sách người dùng đã đọc trong quá khứ. Vì vậy, cần xây dựng một similarity matrix cho tập các cuốn sách này.
Thông thường, các kỹ thuật xử lý ngôn ngữ được áp dụng cho việc trích xuất thông tin từ các content như Count Vector, TF-IDF, CBOW…(có thể tham khảo các kỹ thuật word embeddings tại đây)
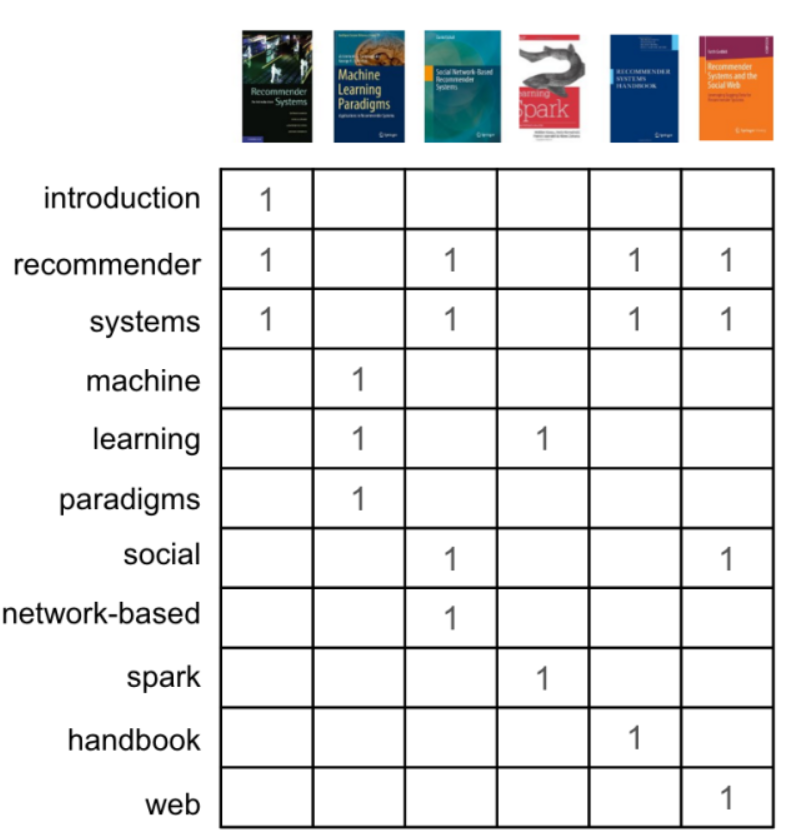
Sau khi xây dựng xong word presentation vector, dễ dàng tính toán được similarity của từng đôi một các cuốn sách. Hình 9 dùng cosine similarity xây dựng một similarity matrix. Để ý rằng các giá trị trên đường chéo chính luôn bằng 1 do tính toán cho chính nó.

Yêu cầu chỉ cho phép đề xuất 2 cuốn sách, dựa vào similarity matrix, chọn ra 2 cuốn sách có similarity cao nhất tương ứng với ba cuốn sách mà người dùng thứ nhất đã đọc:
- Introduction to Recommender System: 2 cuốn sách tương tự là Recommendation System Hanbook và Recommendation System and the Social Web (2 quyển cuối cùng) với cosine similarity lần lượt là 0.67 và 0.58
- Machine Learning Paradigms: Learning Spark (cuốn màu trắng, đỏ có con cá ở giữa) với 0.41
- Recommender System Handbook: Recommendation System and the Social Web và Introduction to Recommender System ứng với 0.58 và 0.67
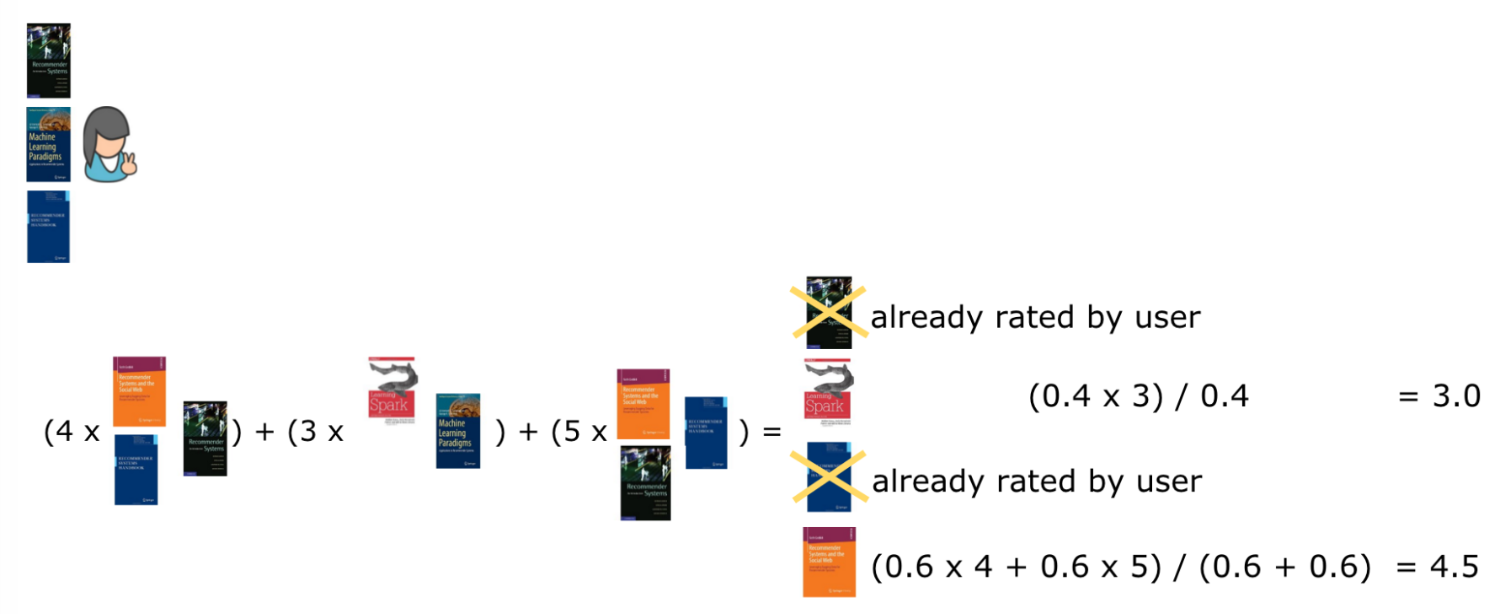
Các sách đã được đọc bởi người dùng cần được loại bỏ khỏi danh sách khuyến nghị, vậy chỉ cần tính toán rating cho 2 cuốn Recommendation System and the Social Web và Learning Spark. Cách tính như sau:
Tổng của (similarity giữa sách đã đọc và sách khuyến nghị * rating của sách đã đọc) / (tổng của similarity giữa sách đã đọc và sách khuyến nghị)
Do sách Recommendation System and the Social Web (cuốn vàng) tương tự với Introduction to Recommender System (0.67) được rating 4 và Recommender System Handbook (0.58) được rating 5 nên công thức tính như hình 10 (similarity chỉ lấy 1 chữ số sau dấy phẩy).
Cách tính cho sách Learning Spark tương tự.
Phần code mẫu cho content-based filtering tại đây
